

Unleashing the Power of Large-Scale Parallel Data Processing on AWS
A Step Function Distributed Map and Lambda Demo


AWS has recently released a new feature for AWS Step Function that allows you to perform large-scale parallel data processing AWS News Article
Why you could need large-scale parallel data processing?
Processing large CSVs or processing every item in an S3 Bucket is something that can be necessary from time to time.
Some examples use cases:
Import data from a large CSV file in a short time
Create many ordered requests to third-party service with retry and backoff, where each request uses the output from the precedent.
Reprocess every image you already have on your S3 bucket to follow a new standard size
Why use serverless resources for it?
Processing millions of items with a tight deadline in a traditional way, using containers or virtual machines, can need quite some effort of pre-provisioning. If our input doesn't come at a predictable time this can be even harder.
By using a combination of services like Step Function and Lambda we can run our workflow without pre-provisioning, run it when needed, and pay only for the usage.
Make sure to verify your AWS Service Limits if you plan to run a large number of Lambda.
Demo
I built a small demo using AWS CDK to run an image resizing process on an S3 bucket containing 8088 images of dogs. The project uses AWS CDK (typescript) and the lambda function executing the processing is built with Go.
The GitHub repository
The dataset used for testing
The Step Function

The step function for this demo is really simple:
{
"Comment": "A description of my state machine",
"StartAt": "Map",
"States": {
"Map": {
"Type": "Map",
"ItemProcessor": {
"ProcessorConfig": {
"Mode": "DISTRIBUTED",
"ExecutionType": "EXPRESS"
},
"StartAt": "Lambda Invoke",
"States": {
"Lambda Invoke": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"OutputPath": "$.Payload",
"Parameters": {
"Payload.$": "$",
"FunctionName.$": "$.BatchInput.lambda_processor_arn"
},
"Retry": [
{
"ErrorEquals": [
"Lambda.ServiceException",
"Lambda.AWSLambdaException",
"Lambda.SdkClientException",
"Lambda.TooManyRequestsException"
],
"IntervalSeconds": 2,
"MaxAttempts": 6,
"BackoffRate": 2
}
],
"End": true
}
}
},
"End": true,
"Label": "Map",
"MaxConcurrency": 1000,
"ItemReader": {
"Resource": "arn:aws:states:::s3:listObjectsV2",
"Parameters": {
"Bucket.$": "$.input.source_bucket_name",
"Prefix.$": "$.input.bucket_path"
}
},
"ItemBatcher": {
"MaxItemsPerBatch": 100,
"BatchInput": {
"lambda_processor_arn.$": "$.input.lambda_processor_arn",
"source_bucket_name.$": "$.input.source_bucket_name",
"destination_bucket_name.$": "$.input.destination_bucket_name"
}
}
}
}
}
We make use of the freshly released DISTRIBUTED mode of the Map state and we create a single Lambda function as a child of this Map state.
We have multiple possible options to use as a source for our distributed processing, in this case, we are using arn:aws:states:::s3:listObjectsV2 that will perform a list operation on the s3 path provided and it will trigger a child execution for each file found (or for a batch in this case, see ItemBatcher item).
Other than the batch settings (the number of items that will go in each child execution) we can also set how many parallel child executions we want with the MaxConcurrency parameter.
In this example I'm setting a batch of 100 items with a max concurrency of 1000 execution, so theoretically the 8088 files will be executed by 81 Lambda functions.
Results
If we run our Step Function we can see the events that take place:
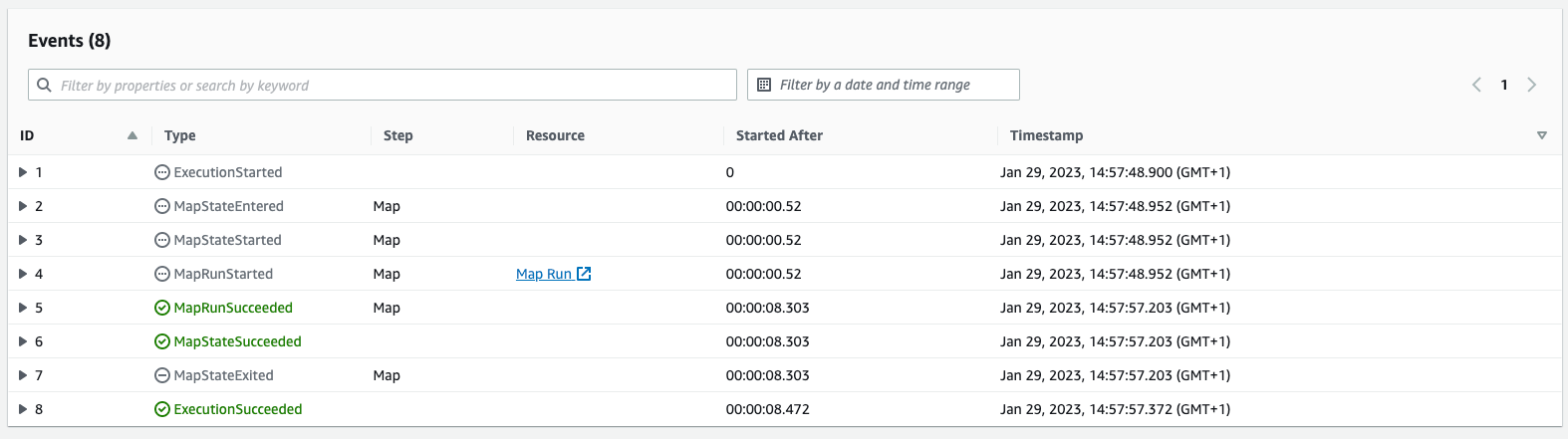
And if we take a look at the Map Run dashboard we can see the details about the child executions of the Step Function:

With these batch settings, we run the resizing process on 8088 photos in just 8.4 seconds, and if we take a look at Lambda metrics we can see that Lambda duration has an average value of 2.3 seconds and we have exactly 81 invocations with 81 concurrent executions, so exactly what we were expecting.
I also did run an experiment with a batch size of 10 and 809 invocations were triggered with a peak of 341 concurrent execution and an average duration of 432ms.
Our resized dog:
